Успешно завершен бенчмарк RNNCB, запущенный ООО "Аватар Машина" в партнерстве с АЛРИИ
Каждая команда показала уникальный подход, доказав, что on-prem RAG решения могут быть отличными. Любые даже небольшие улучшения в ИИ-моделях могут изменить индустрию. Поэтому распределить места было трудно, но пул из LLM-судей справился с задачей блестяще, обеспечив прозрачную и воспроизводимую оценку качества ответов
Критерии оценки языковых моделей:
Более подробная информация об исследовании и его инсайтах появится в публикации в СМИ. Лидерборд уже доступен на сайте.
В ближайшее время в Лидерборде будут размещены участники.
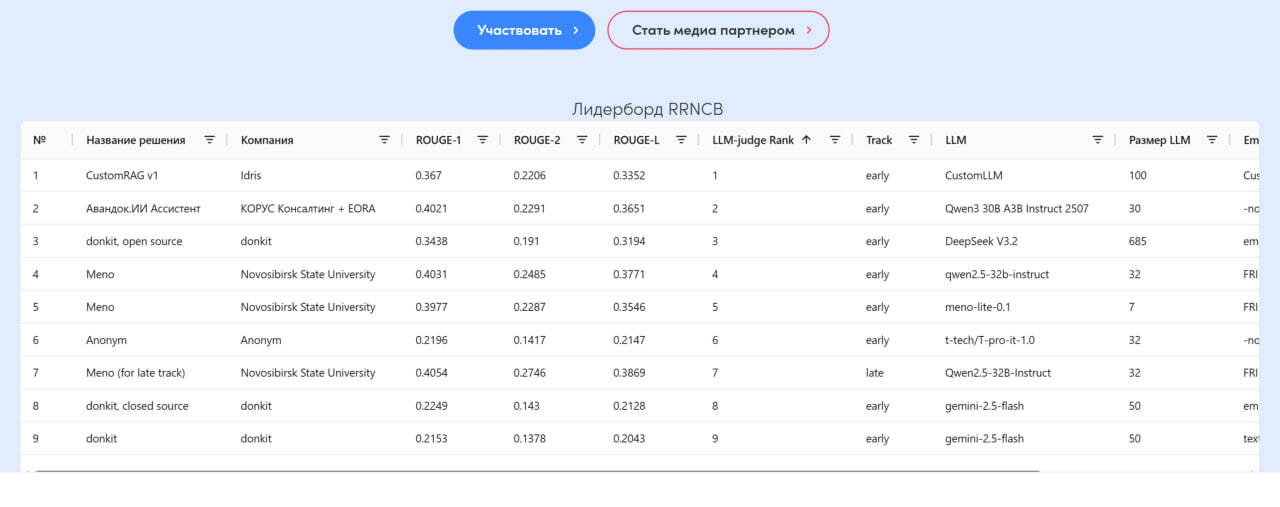
Список лидеров
⏺Первое место — CustomRAG v1 от команды Idris
Облачное решение (исходя из размера LLM в 100b)
Особенность - есть своя модификация LLM и эмбеддингов, модифицированный поиск
⏺Второе место — Авандок. ИИ Ассистент от команды КОРУС Консалтинг + EORA
Особенность - сборка на открытой модели Qwen3 30B A3B Instruct 2507 показывает, что результат можно получить и на небольших моделях.
Лучшее решение по соотношению качество/размер LLM
⏺Третье место — donkit, open source от команды Donkit AI.
Решение на китайской DeepSeek V3.2 с векторным поиском на qdrant.
Особенность - модель эмбеддингов EmbeddingGemma с 308 млн параметров, новым лидером среди компактных моделей до 500 млн параметров. Решение очень экономичное по стоимости
⏺Четвертое место — Meno от команды Novosibirsk State University.
Решение от НГУ, команды университета на базе qwen2.5-32b-instruct.
Особенность - единственная команда с сабмитом на базе компактной модели на 7b (тюн T-lite на основе авторской методики curriculum learning. learning. Сделано несколько сабмитов для улучшения, в том числе и в late track. Сочетает компактный размер и неплохое качество
⏺Пятое место — Anonym от команды Anonym. (Крупная компания с госучастием, пожелали выступить анонимно)
Особенность - единственное решение на российской модели t-tech/T-pro-it-1.0 от Т-банка, дообученной Qwen 2.5 с continual pre-training and alignment techniques на русскоязычных датасетах Common Crawl, книгах, коде, с частью закрытых проприетарных. Решение доказывает промышленную применимость российских моделей
Каждая команда показала уникальный подход, доказав, что on-prem RAG решения могут быть отличными. Любые даже небольшие улучшения в ИИ-моделях могут изменить индустрию. Поэтому распределить места было трудно, но пул из LLM-судей справился с задачей блестяще, обеспечив прозрачную и воспроизводимую оценку качества ответов
Критерии оценки языковых моделей:
- factual (фактологическая точность - соответствие эталону по фактам и цифрам)
- completeness (полнота ответа - охват всех важных аспектов из эталона)
- structure (структурированность - логичность изложения, читаемость)
- relevance (Релевантность - отсутствие информации, не относящейся к вопросу)
- ROUGE-1, ROUGE-2, ROUGE-L для расчета пересечения последовательностей слов
Более подробная информация об исследовании и его инсайтах появится в публикации в СМИ. Лидерборд уже доступен на сайте.
В ближайшее время в Лидерборде будут размещены участники.
Список лидеров
⏺Первое место — CustomRAG v1 от команды Idris
Облачное решение (исходя из размера LLM в 100b)
Особенность - есть своя модификация LLM и эмбеддингов, модифицированный поиск
⏺Второе место — Авандок. ИИ Ассистент от команды КОРУС Консалтинг + EORA
Особенность - сборка на открытой модели Qwen3 30B A3B Instruct 2507 показывает, что результат можно получить и на небольших моделях.
Лучшее решение по соотношению качество/размер LLM
⏺Третье место — donkit, open source от команды Donkit AI.
Решение на китайской DeepSeek V3.2 с векторным поиском на qdrant.
Особенность - модель эмбеддингов EmbeddingGemma с 308 млн параметров, новым лидером среди компактных моделей до 500 млн параметров. Решение очень экономичное по стоимости
⏺Четвертое место — Meno от команды Novosibirsk State University.
Решение от НГУ, команды университета на базе qwen2.5-32b-instruct.
Особенность - единственная команда с сабмитом на базе компактной модели на 7b (тюн T-lite на основе авторской методики curriculum learning. learning. Сделано несколько сабмитов для улучшения, в том числе и в late track. Сочетает компактный размер и неплохое качество
⏺Пятое место — Anonym от команды Anonym. (Крупная компания с госучастием, пожелали выступить анонимно)
Особенность - единственное решение на российской модели t-tech/T-pro-it-1.0 от Т-банка, дообученной Qwen 2.5 с continual pre-training and alignment techniques на русскоязычных датасетах Common Crawl, книгах, коде, с частью закрытых проприетарных. Решение доказывает промышленную применимость российских моделей